

Upserts are useful for anyone who works with a database to know, but the term “upsert” might not even appear in your DBMS’s documentation!
So what is an upsert, anyway? And why might it not be mentioned in your docs?
What is an upsert in SQL?
The term upsert is a portmanteau – a combination of the words “update” and “insert.” In the context of relational databases, an upsert is a database operation that will update an existing row if a specified value already exists in a table, and insert a new row if the specified value doesn’t already exist.
For example, imagine we have a database with a table employees and an id column as the primary key:
We could use an upsert when changing employee information in this table. Logically, that would look like this:
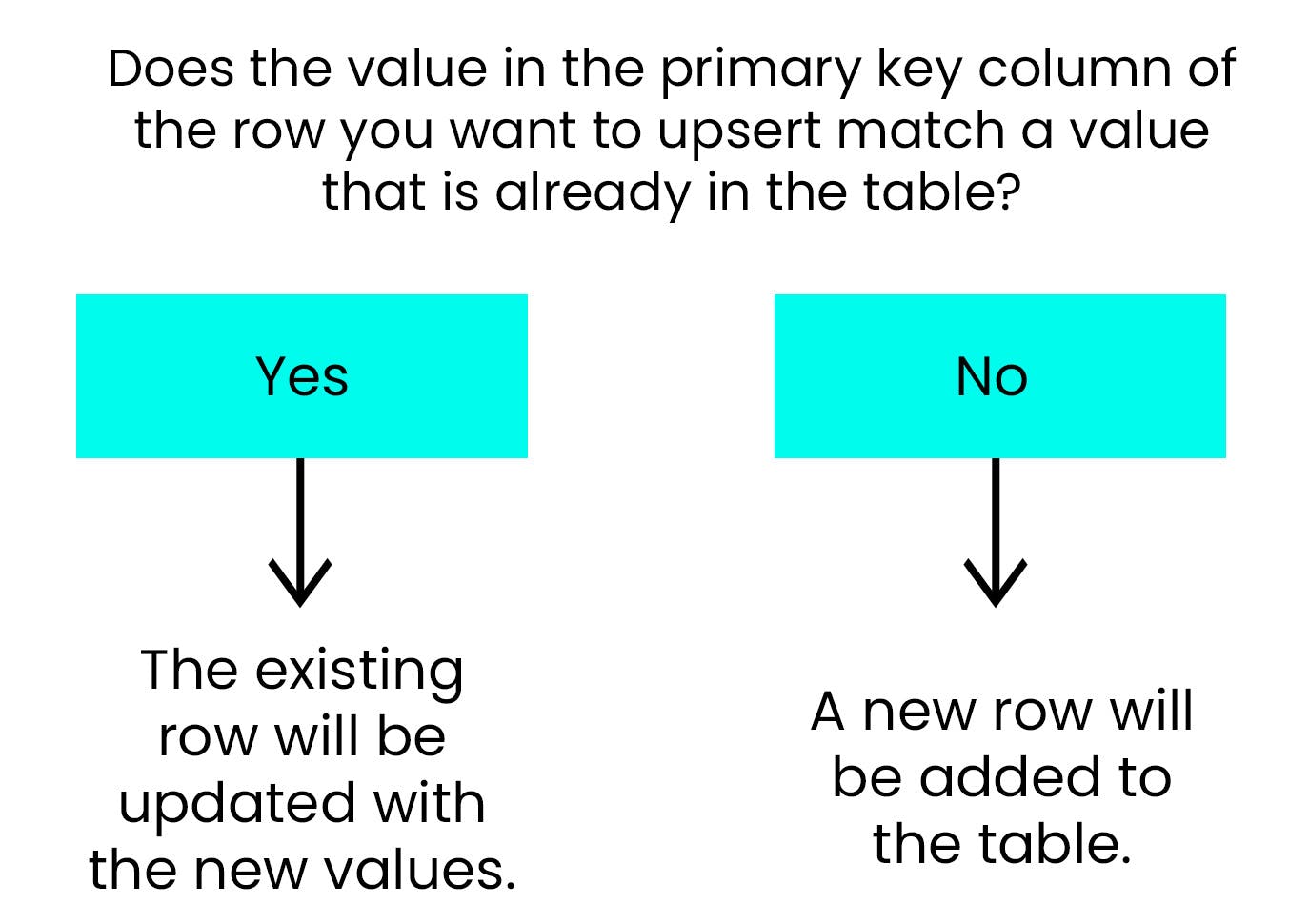
If the employee ID exists in the table, update that row with the new information.
If the employee ID doesn’t exist in the table, add it as a new row.
Different RDBMS handle syntax for upserts differently – we’ll get to that a little later – but using CockroachDB UPSERT syntax, here are a couple of example SQL statements, and the employees table that would result if each statement was run:
Example #1
UPSERT INTO employees (id, name, email) VALUES (2, ‘Dennis’, ‘dennisp@weyland.corp’);Result:
In this example, the primary key value of 2 already exists in the table, so the UPSERT operation updated that row with the new values for name and email.
Example #2
UPSERT INTO employees (id, name, email) VALUES (3, ‘Ash’, ‘ash@hyperdyne.corp’);Result:
In this example, the primary key value of 3 does not already exist in the table, so the UPSERT operation inserts a new row into the table with the relevant values.
However, this is just a simple example. In fact, in many RDBMS, UPSERT doesn’t even exist as a command! This is why if you search the documentation for your database of choice, you might not find an entry for “upsert.”
We can perform upserts in most popular databases, however, so let’s take a look at how to do them in MySQL and PostgreSQL before circling back to CockroachDB to discuss some of the details.
RELATED
SQL cheat sheet: SQL basics for developers, with examples
We’ll continue to use our sample employees table to demonstrate how these work.
Upsert in MySQL
The UPSERT command doesn’t exist in MySQL, but upserts can still be achieved. The best method for implementing an upsert in the current version of MySQL is INSERT … ON DUPLICATE KEY UPDATE . Let’s look at that command in a bit more detail.
As the command itself suggests, INSERT … ON DUPLICATE KEY UPDATE will insert a new row into a table unless it detects a duplicate value in the primary key column, in which case it will update the existing row with the new information.
So, if we were to run the following command on the example employees table…
INSERT INTO employees (id, name, email) VALUES (2, ‘Dennis’, ‘dennisp@weyland.corp’) ON DUPLICATE KEY UPDATE;…we would get the same results as we saw in Example #1 above. MySQL detects that the value 2 already exists in the primary key column id, so it updates that row with the new information.
Similarly, if we were to run that same command with the values (4, ‘Dallas’, ‘dallas@weyland.corp’), it would insert a new row into employees with those values, because the value 4 does not exist in the example table.
Upsert in PostgreSQL
PostgreSQL also doesn’t have a dedicated UPSERT command, but upserts can be accomplished using INSERT ON CONFLICT. This command can be a bit more complicated than INSERT … ON DUPLICATE KEY, but it also allows us to have more control.
Let’s start by taking a look at the basic structure of an INSERT ON CONFLICT statement in Postgres:
INSERT INTO table (col1, col2, col3)
VALUES (val1, val2, val3)
ON CONFLICT conflict_target conflict_action;As we can see in the above command, PostgreSQL allows us to specify two things:
conflict_target, i.e. where it should look to detect a conflict.
conflict_action, i.e. how the command should be handled if a conflict is detected.
This allows us to be a little more targeted in how our upserts are applied.
In the current version of PostgreSQL INSERT, we can achieve a basic upsert by specifying the conflict target (in this case id, the primary key column) and what we want to do if a conflict is detected (in this case, update the existing row):
INSERT INTO employees (id, name, email)
VALUES (2, ‘Dennis’, ‘dennisp@weyland.corp’)
ON CONFLICT (id) DO UPDATE;Running this command would produce the same results as in Example #1 at the beginning of this article. PostgreSQL detects a conflict – we’re trying to insert a row with an id value of 2, but a row with that id already exists in employees – so it runs UPDATE on that row using the new values.
If we were to run this command with values that did not generate a conflict (for example, (5, ‘Kane’, ‘kane@weyland.corp’), it would insert a new row into employees with those values.
UPSERT in CockroachDB
CockroachDB does have an UPSERT command, and like PostgreSQL, upserts can also be achieved using INSERT ON CONFLICT.
While these two commands can achieve similar results, they’re not exactly the same. Let’s take a look at how they differ, and when we might want to use each.
UPSERT vs. INSERT ON CONFLICT
The UPSERT command in CockroachDB performs an upsert based on the uniqueness of the primary key column or columns, and it will perform an UPDATE or INSERT depending on whether the values being added are unique.
This makes using UPSERT a bit more straightforward than INSERT ON CONFLICT, since we don’t need to specify a conflict target or action. For example, running the following statement against our example employees table…
UPSERT INTO employees (id, name, email) VALUES (6, ‘Lambert’, ‘lambert@weyland.corp`);…will result in the following table:
Because the value of 6 doesn’t already exist in employees, CockroachDB inserts the values into the table as a new row.
Similarly, if we were to run the following statement…
UPSERT INTO employees (id, name, email) VALUES (1, ‘Ripley’, ‘ripley@weyland.corp`);…we would get the following table:
Because the 1 already exists in id, the primary key column, CockroachDB updates that row with the new information.
However, with CockroachDB we also have the flexibility of using INSERT ON CONFLICT, which could be useful in some circumstances. For example, we could use INSERT ON CONFLICT to handle upserts in situations where we want to avoid conflicts that aren’t related to the primary key. For example, we could specify a foreign key column as the conflict target.
There are also sometimes performance differences between UPSERT and INSERT ON CONFLICT, though these will depend on the specifics of your workloads. See the CockroachDB UPSERT docs for more info.




